How to Fine-Tune BERT for Named Entity Recognition
How to Fine-Tune BERT for Named Entity Recognition
Name Entity 是什麼?
所謂的Name Entity,是自然語言處理中的一項任務,也跟資訊檢索中的資訊擷取議題有關。在全文文件中,常有人名、地名、機構名等詞彙出現,以及關於時間、金錢等不同格式數據的表達,這些詞彙經常不會出現在既有的詞庫中,因此需要特別的標註,以便擷取及應用。以此句為例:「2006年10月9日,Google宣布以16.5億美元的股票收購YouTube網站。」,專有名詞標記需將:「2006年10月9日」標註成時間名詞並轉換成日期,「Google」、「YouTube」標註為組織名,「16.5億美元」標註為金錢數量。
如何訂定Name Entity?
我們通常在訂定Name Entity的時候,通常會從有兩個點依序下去思考: 這個domain有哪些可能的task。 那每個task可能會需要知道的Name Entity。 基本上基於這兩個點,我們才不會定義出不相關的或是未來可能還有該辨識的但是當初沒有定義到。 我們可以看出來Name Entity呼應到了開頭提到的,在特定應用場景下,跟特定task相關的元素。 我想有些朋友讀到這邊會產生出另外一個疑問,假如Name Entity都是domain specific,那麼為什麼會有一些general entity呢? 其實是這樣子的,所謂的general entity也是基於某一個domain (一般群眾在一般生活環境)去訂定的。這邊列舉一些general entity:
- Stanford typical 3 classes:
LOCATION, ORGANIZATION, PERSON - Stanford typical 7 classes:
DATE, LOCATION, MONEY, ORGANIZATION, PERCENT, PERSON, TIME - Stanford typical 4 classes:
LOCATION, MISC, ORGANIZATION, PERSON
但假如我在不同的應用中,舉例來說刑事案件中,對於PLACE來說,我可能還會有不同的Entity像是命案現場、發現現場等,到底是哪個entity還是要再根據上下文去做判斷。
Name Entity Recognition Method
- 基於規則和字典的方法:
此方法是基於專家知識制定出模板及規則,並透過統計資訊、關鍵字、標點符號、位置詞等等眾多詞彙當作特徵進行字串匹配為主要的手段,這類系統大多依賴於知識庫和詞典的建立。
例如使用POS Pattern來進行Entity查找,它就是藉由統計Entity 底下某種POS Pattern出現的機率來設計,例如動詞接名詞的Pattern就定義為事件。 ex 喝咖啡、看電影、吹乒乓球。
- 基於統計機器學習的方法:
在基於機器學習的方法中,NER被當作序列標註問題。利用大規模語料來學習出標註模型,從而對句子的各個位置進行標註。NER 任務中的常用模型包括生成式模型HMM、判別式模型CRF等。條件隨機場(Conditional Random Field,CRF)是NER目前的主流模型。
HMM主要就是在計算狀態之間轉移機率,因句子本來就是一個具有順序的資料,也就是說詞跟詞之前的轉換,可以視為一個狀態轉到下一個狀態的架構,我們主要就是在計算狀態跟狀態轉換的機率。
條件隨機場(CRF) 的目標函數不僅考慮輸入的狀態特徵函數,而且還包含了標籤轉移特徵函數。在訓練時可以使用SGD學習模型參數。在已知模型時,給輸入序列求預測輸出序列即求使目標函數最大化的最優序列,是一個動態規劃問題,可以使用維特比算法進行解碼。CRF的優點在於其爲一個位置進行標註的過程中可以利用豐富的內部及上下文特徵信息。
- 基於深度學習的方法:
主要就是將token從離散one-hot表示映射到低維空間中成為稠密的embedding,隨後將句子的embedding輸入到深度學習中對於處理序列性資料有很好效果的RNN中,用神經網絡自動提取特徵,Softmax來預測每個token的標籤。這種方法使得模型的訓練成為一個端到端的過程,而非傳統的pipeline,不依賴於特徵工程,是一種數據驅動的方法,但網絡種類繁多、對參數設置依賴大,模型可解釋性差。此外,這種方法的一個缺點是對每個token打標籤的過程是獨立的進行,不能直接利用上文已經預測的標籤(只能靠隱含狀態傳遞上文信息),進而導致預測出的標籤序列可能是無效的,例如標籤I-PER後面是不可能緊跟著B-PER的,但Softmax不會利用到這個信息。所以學界提出了DL-CRF模型做序列標註。在神經網絡的輸出層接入CRF層(重點是利用標籤轉移機率)來做句子級別的標籤預測,使得標註過程不再是對各個token獨立分類。
而現在最流行的便是biLSTM-CRF模型主要由Embedding層(主要有詞向量,字向量以及一些額外特徵),雙向LSTM層(不只可以學習由左到右的信息,甚至由右到左的信息都學的到),以及最後的CRF層構成。實驗結果表明biLSTM-CRF已經達到或者超過了基於豐富特徵的CRF模型,成為目前基於深度學習的NER方法中的最主流模型。在特徵方面,該模型繼承了深度學習方法的優勢,無需特徵工程,使用詞向量以及字符向量就可以達到很好的效果,如果有高質量的詞典特徵,能夠進一步獲得提高。
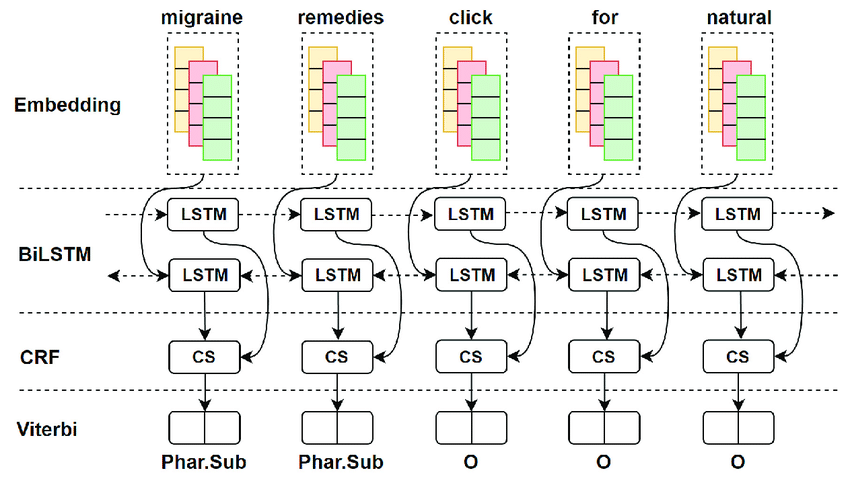
- 基於注意力機制和半監督式學習方法:
主要就是因為隨着Bert語言模型在NLP領域橫掃了11項任務的最優結果,將其在命名實體識別中Fine-tune必然成爲趨勢。它主要是使用bert模型替換了原來網絡的word2vec部分,從而構成Embedding層,同樣使用雙向LSTM層以及最後的CRF層來完成序列預測,簡而言之可以理解成bert同樣也是產生embedding的工具,只不過這個embedding比Word2vec的embedding要厲害,因為bert的embedding是可以先經由其它任務去pre-train它的模型。
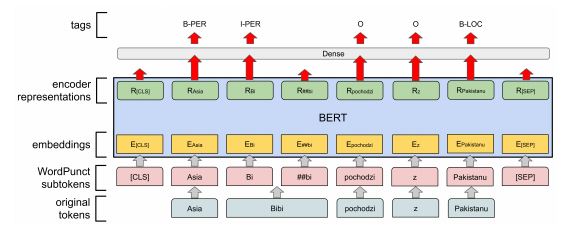
如何處理將資料及標籤處理成Bert輸入
處理完原始數據以後,最關鍵的就是了解如何讓BERT讀取這些數據以做訓練和推論。這時候我們需要了解 BERT的輸入編碼格式。 這步驟是本文的精華所在,你將看到在其他只單純說明BERT概念的文章不會提及的所有實務細節。以下是原論文裡頭展示的成對句子編碼示意圖:
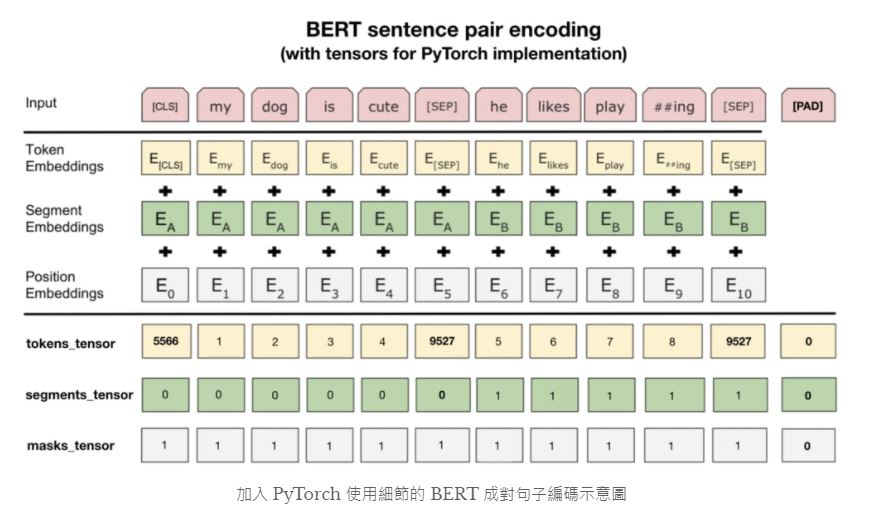
第二條分隔線之上的內容是論文裡展示的例子。圖中的每個 Token Embedding 都對應到前面提過的一個 wordpiece,而 Segment Embeddings 則代表不同句子的位置,是學出來的。Positional Embeddings 則跟其他 Transformer 架構中出現的位置編碼同出一轍。
實際運用 PyTorch 的 BERT 時最重要的則是在第二條分隔線之下的資訊。我們需要將原始文本轉換成 3 種 id tensors:
- tokens_tensor:代表識別每個 token 的索引值,用 tokenizer 轉換即可
- segments_tensor:用來識別句子界限。第一句為 0,第二句則為 1。另外注意句子間的 [SEP] 為 0
- masks_tensor:用來界定自注意力機制範圍。1 讓 BERT 關注該位置,0 則代表是 padding 不需關注
論文裡的例子並沒有說明 [PAD] token,但實務上每個 batch 裡頭的輸入序列長短不一,為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致。另外 masks_tensor 以及 segments_tensor 在 [PAD] 對應位置的值也都是 0。
輸入句子 :
Thousands of demonstrators have marched through London to protest the war in Iraq and demand the withdrawal of British troops from that country .
轉成Bert輸入結果:
代碼中的數據就是轉成這樣,這部分是純屬工程問題。
word_tokens: ['[CLS]', 'Thousands', 'of', 'demons', '##tra', '##tors', 'have', 'marched', 'through', 'London', 'to', 'protest', 'the', 'war', 'in', 'Iraq', 'and', 'demand', 'the', 'withdrawal', 'of', 'British', 'troops', 'from', 'that', 'country', '.', '[SEP]']
tokens_tensor: [101, 26159, 1104, 8568, 4487, 5067, 1138, 9639, 1194, 1498, 1106, 5641, 1103, 1594, 1107, 5008, 1105, 4555, 1103, 10602, 1104, 1418, 2830, 1121, 1115, 1583, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
segments_tensor: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
masks_tensor: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
label_tensor: [-100, 14, 14, 14, -100, -100, 14, 14, 14, 12, 14, 14, 14, 14, 14, 12, 14, 14, 14, 14, 14, 2, 14, 14, 14, 14, 14, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]
上面tokens_tensor、segments_tensor及masks_tensor 上的0是為了padding最大輸入長度而加上的,在此模型最大的輸入長度是512,而segments_tensor是只輸入一條句子,則label_tensor的-100是使用交叉熵時用此padding id,以便以後計算損失只看真實標籤id。
設定多GPU進行訓練
# 設定CUDA和計算有多少顆GPU可用
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = torch.cuda.device_count()
# 主要是將訓練資料根據可得的運算資源,分割成一或更多的訓練資料子集,分配到id為0和1的運算單元中執行,以達到平行的策略。
if args.n_gpu > 1:
model = torch.nn.DataParallel(model, device_ids=[0,1])
更新參數
主要就是根據args.gradient_accumulation_steps這個參數來決定執行多少個step去更新參數,optimizer.step()是根據梯度更新參數,model.zero_grad()則是直接將模型的梯度清為零。
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
scheduler.step() # Update learning rate schedule
optimizer.step()
model.zero_grad()
global_step += 1
輸出結果
input: The International Atomic Energy Agency is to hold second day of talks in Vienna Wednesday on how to respond to Iran's resumption of low-level uranium conversion .
result: [('The', 'O'), ('International', 'B-org'), ('Atomic', 'I-org'), ('Energy', 'I-org'), ('Agency', 'I-org'), ('is', 'O'), ('to', 'O'), ('hold', 'O'), ('second', 'O'), ('day', 'O'), ('of', 'O'), ('talks', 'O'), ('in', 'O'), ('Vienna', 'B-geo'), ('Wednesday', 'B-tim'), ('on', 'O'), ('how', 'O'), ('to', 'O'), ('respond', 'O'), ('to', 'O'), ('Iran', 'B-gpe'), ("'", 'O'), ('s', 'O'), ('re', 'O'), ('##sumption', 'O'), ('of', 'O'), ('low', 'O'), ('-', 'O'), ('level', 'O'), ('uranium', 'O'), ('conversion', 'O'), ('.', 'O')]